Argo Workflow
Argo Workflows is an open source container-native workflow engine for orchestrating parallel jobs on Kubernetes. We used this to perform some specific operations to finish product onboarding process, including communication with SAP BTP and configuration setting in subaccount and Kubernetes namespace.
1. Argo Workflow Installation
The installation command is as simple as:
kubectl apply -n [namespace] -f [filename]
We only need to clarify the namespace we want to install argo workflow in, say a namespace named shared. Also we need to confirm the installation file and put it in the current directory path. It would be OK to use the installation file provided in the official guide, while there are some details requiring modification:
-
For service account configuration, we need to clarify the namespace, and the namespace must match the very namespace we write in the command:
- kind: ServiceAccount name: argo namespace: shared --- - kind: ServiceAccount name: argo-server namespace: shared -
In this ConfigMap part, we need to make sure which kind of executor used in the Kubernetes environment, and set up related field, aka
containerRuntimeExecutorin the installation file. For example, Kind uses container and the executor should be set aspns(Pod Namespace Sharing); While in our online Kubernetes environment, we need to set the field ask8sapi. The whole configuration then is like:apiVersion: v1 kind: ConfigMap metadata: name: workflow-controller-configmap data: config: | containerRuntimeExecutor: k8sapiBy the way, the default value of the
containerRuntimeExecutorisdocker.
After being installed successfully, you should see argo-server and workflow-controller deployed in the very namespace.
2. Monitor workflows
There is an out-of-the-box frontend page to monitor all the workflows with many other features. To use it, firstly we need to do a port-forward:
kubectl -n [namespace] port-forward deployment/argo-server 2746:2746
And then visit the url in bowser:
https://localhost:2746/workflows/shared?limit=500
In the page, we could view all the workflows submitted and their status, like running, success and failed. We could also view detailed information by clicking in, including logs during running and parameters passed in and out.
3. Submit Workflow
Workflow should be submitted in Yaml or Json format, an example given by official guideline is like:
apiVersion: argoproj.io/v1alpha1
kind: Workflow # new type of k8s spec
metadata:
generateName: hello-world- # name of the workflow spec
spec:
entrypoint: whalesay # invoke the whalesay template
templates:
- name: whalesay # name of the template
container:
image: docker/whalesay
command: [cowsay]
args: ["hello world"]
resources: # limit the resources
limits:
memory: 32Mi
cpu: 100m
The core concept of Argo Workflow is simple: This is just a workflow, and in each step, it would use specific docker images to run specific commands to finish specific purposes. This is just a simple example, and Argo Workflow could be behave complex behaviors including parallel running, condition running and so on. For this part, you could refer to official guideline.
But this method involves human interaction, because we have to manually submit a yaml file, for example. And we need to automate it. There are some solutions provided by Argo community, including Argo Events and some other tools. For our purpose, they are too heavy or hard to use, while the APIs provided by argo controller are just enough to meet out requirements.
The APIs could be checked at the monitoring page I mentioned above, and there are the most useful APIs (I believe):
- Submit workflow:
POST /api/v1/event-sources/{namespace}. In this API, we need to submit the workflow template in Json format, and the monitoring page just provides a tool to convert workflow template from Yaml format (most commonly used) to Json format. - Query workflow:
GET /api/v1/event-sources/{namespace}/{name}. By specifying the name of the workflow, or just used@latestto fetch the latest submitted workflow, we could see all the logs of the workflow as well as its status. - Delete workflow:
DELETE /api/v1/event-sources/{namespace}/{name}.
Besides these APIs, we also need a service to do the operation of submitting the workflow. The service should involve a template, and fill in necessary information. In our requirements, this service should also receive request to trigger a workflow and deal with passed in parameters. In this way, I put a workflow template in Json format in the service, and the service could read it, replace %s marks with real parameters and then send it to argo controller with Http call. On the other hand, the API of submitting workflow is asynchronous, while the requirement is to provide synchronized API for upstream service, so that the query API is needed. The service would check the status of its submitted workflow routinely and there is also a counter against infinite loop with a time-out failure message.
4. Workflow Content
Each workflow consists of several docker images and related commands. In our workflow template, we have three steps and three docker images involved currently. In each of step we perform a single job, divided by function.
1. Create Subaccount
The first step is to create a subaccount under certain global account SAP BTP. The APIs are public and familiar to use, and we need to fetch data from shared-meta service. In our practice, we do not store these data directly in our codebase because of security issues, and these data would be retrieved by trigger service and passed through workflow template.
The subaccount creation API is asynchronous and we need to query the creation status routinely like we have mention above. The creation could fail for different reasons, like duplicated domain name or authorization issues.
2. Register Platform
This operation happens on SAP BTP within subaccount, and public APIs are also available.
3. Install Proxy
This step involves Helm operation, which requires administrative rights. This is really troublesome, because a container running on Helm image would not be granted this kind of rights without additional configuration. In fact, this kind of configuration could be really straightforward: we need to put a Kubeconfig file in the project, and apply it while running commands. I have also referred to colleagues from infrastructure team and they said no other ways to gain these rights. They used to deal with this scenario by sending the content of Kubeconfig file to the container after being encoded with base64, which is safer but still involving Kubeconfig file. In a word, we would not get rid of the file, and because we need to deploy and run our workflow in different clusters, we need to prepare related Kubeconfig files separately and use them accordingly.
5. The Whole Diagram
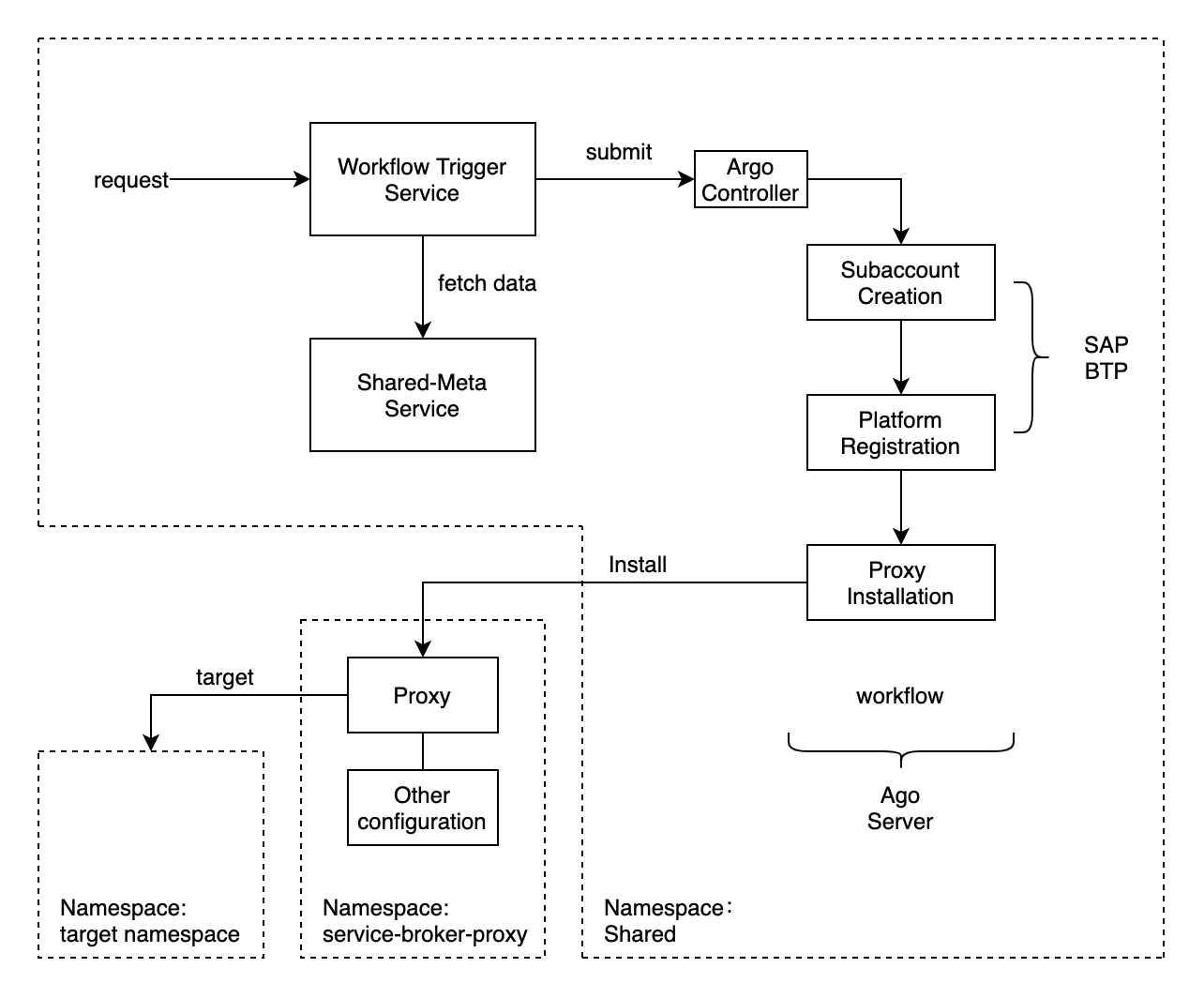
6. Future Work
There is still something requiring being finished in the future:
- Workflow trigger service needs a database to store whether a subaccount has been created or a proxy has been installed for a specific namespace. In this way, each request for workflow trigger service should be idempotent, and if the service has detected that a request is duplicated, it could just ignore the request and simply return 200 OK as the respond.
- A clean-up workflow should be triggered if something goes wrong while running the creation&installation workflow. As the original workflow goes from up to bottom, the clean-up workflow should go from bottom to up, that is to say, it needs to uninstall proxy, then unregister the platform, and finally delete the subaccount. But we also need to notice that each step could fail and following steps would not be performed, and the clean-up workflow must have the ability to handle this.